
微信扫码咨询
废话不多说了,看代码吧~
select
row_number() over(order by 业务号,主键,排序号) rn -- 行号
,count(0) over() cnt -- 总条数
,id
from 表
order by 排序号,主键,业务号
offset (页号- 1)* 每页数量 limit 每页数量
补充:postgreSQL单表数据量上千万分页查询缓慢的优化方案
故事要这样说起,w是一个初入职场的程序猿,每天干的活就是实现各种简单的查询业务,但是铁蛋有一颗热爱技术的心,每天都琢磨着如何写出花式的增删改查操作。没错平凡的铁蛋的有着一个伟大的梦想,成为一名高级CRUDER。
时间就这样一天天的流逝,w感觉不管自己的crud写的再花骚也不能达到高级cruder的级别,于是乎w心一横,接下了一个艰巨的任务,对单表数据量到百万千万级别的查询页面进行优化,这是w工作任务上的一小步,却是w实现梦想的一大步。
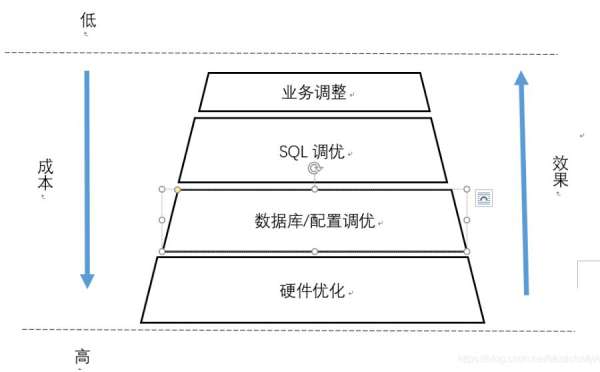
接任务简单,做任务难呀! 这是w第一天的感受,接了这个任务之后w没有一点头绪,从哪下手呢?w仔细一想既然要优化,那么总得知道 哪里需要优化吧? 可以从哪些方面优化吧? 需要知道最如何分析瓶颈在哪吧? 不料天降神图,给了一个指引, 没错就是数据库可以优化的方向图。
注:图中效果的渐变其实不太准确, 但是总的来说如果不是SQL写的特别烂的话大体上优化这些不同的方面对性能的影响是以图中的示意变化的。
虽然有了神图的指引,但是w还是不知道应该优化哪个方面? 不同方面的优化方式是什么?一番努力查找,得到了以下信息:
从成本方面考虑,土豪的优化方式向来简单粗暴,硬件不行就换硬件嘛, 不差钱!!! 但是w不行呀,草根一枚,要钱没钱, 要人没人,只能选择便宜的来下手了。柿子嘛还是得挑软的捏,于是乎,w踌躇满志的找产品商量改需求。
咳咳 !!!!怎么说呢? w为了降低成本,为公司控本降费,初心是好的,但是呀这个做法嗯嗯啊啊。。。, 大家以此为戒哦!!!
既然改需求不行,那就只能往下走了, 先来一波SQL优化看看,要优化SQL总得知道SQL慢在哪里了吧?
咋办咋办! 不知道哪里慢咋办?
还能咋办,看SQL的执行计划呗!
不会看咋办?
啥! 不会看, 不会看学啊!
好吧,当我没问!!!
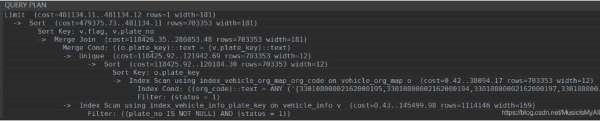
怎么看执行计划呢,首先你得会一个SQL的命令,叫EXPLAIN, 此命令用于查看SQL的执行计划。得此命令,铁蛋如获至宝, 拿起来就是一顿操作,看到命令输出的结果后,w傻眼了,这什么鬼? 这怎么看?
怎么看??? 用眼睛看呗,还能怎么看。
总的来说sql的执行计划是一个树形层次结构, 一般来说阅读上遵从层级越深越优先, 同一层级由上到下的原则。
来跟着读: 层级越深越优先, 同一层级上到下。
顺序知道了,得知道里面的意思了吧, 是的没错, 但是这个里面比较具体的一些细节这里就不再展开了,只介绍比较常关注的几个关键字:
重点来了,重点来了,睡觉的玩手机的停一停。老师要开车了, 啊呸, 开课了。
第一行的括号中从左到右依次代表的是:
(估计)启动成本,在开始输出之前花费的时间,例如排序时间。
(估计)总成本, 这里有一个前提是计划节点会完整运行,即所有可用行都会被检索。实际上一些节点的父节点不会检索所有可用行(如LIMIT)。
(估计)输出的总行数,同样的是基于节点会完整运行的假设。
(估计)输出行的平均宽度(以字节为单位)
注意:
cost中描述的是启动成本和总成本,但是到目前为止我们还不知道这个数字代表的具体含义,因为我们不知道它的单位是什么。(所以说这里cost中的成本是具有相对意义,不具有绝对意义)
rows代表的是输出的总行数,他不是计划节点处理或扫描的行数,而是节点发出的行数。由于使用where子句过滤,这个值通常小于扫描的数目。理想情况下,顶级的rows近似于实际的查询返回,更新或删除的行数
上图中的 Index Scan代表索引扫描, Index Cond代表索引命中,后面是命中的具体的索引; Filter是过滤条件,跟具体的sql有关, 注意sort, sort中应该是有两行,下面的图示中能够看到, 第一行代表对那个键进行排序, 第二行是排序方法(主要有内存排序和磁盘排序,应该避免磁盘排序)和数据大小。
explain还有两个比较有用的参数一个是analyze, 一个是buffers。 加上第一个参数可以让sql真正的执行并且预估执行时间, 第二参数可以查看缓存命中情况。
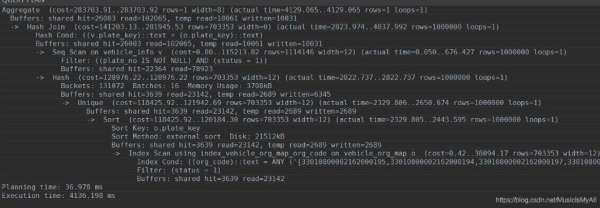
actual time对应的意义和cost相似,但是不同于cost, actual time具有绝对意义,因为它的单位是ms。loops代表循环的次数。
缓存命中情况主要看Buffers这一行, hit就是命中情况,buffers的信息有助于确定查询的哪部分是IO密集型的。
Hash节点主要看 Buckes, 哈希桶的数量, Batches:批处理的数量,批处理的数量如果超过1,则还会使用磁盘空间,但不会显示。 Memory Usage代表内存的使用峰值。
有了以上信息我们基本上就可以寻医问药, 对症下药了, 该建索引的建索引, 查询语句没有命中索引的调整下sql,联合索引条件过滤包含驱动列,且驱动列在前效率最高。
索引优化小技巧:
索引尽量建在数据比较分散的列上, 不要在变化很小的字段上加索引,比如性别之类的。
原因就是:
索引本质上是一种空间换时间的操作,通过B Tree这种数据结构减少io的操作次数以此来提升速度。如果在变化很小的字段上建立索引,那么可能单个叶子节点上的数据量也是庞大的,反而增加了io的次数(如果查询字段有包含非索引列,索引命中之后还需要回表)
到了这里就开始我们题目中的正文了, 分页查询性能优化!!!
怎么优化呢? 经过上述一系列的索引和sql优化之后,铁蛋老师发现虽然sql的执行速度比以前快了,但是在单表一千万的量级下,这个查询的速度还是有点龟速呀。
仔细看了上图中的执行计划发现有三个个地方有嫌疑,一个是Hash节点, 一个是Sort, 还有一个是Buffers。
在Hash节点中Batches批处理的数量超过了1, 这说明用到了外存, 原来是内存不够了呀!
Sort节点中,排序方法是归并, 而且是磁盘排序, 原来也是内存不够了。
Buffers 节点中,同一个sql执行两次每次都有新的io,说明缓存空间也不够,最终这三个现象都指向了内存。
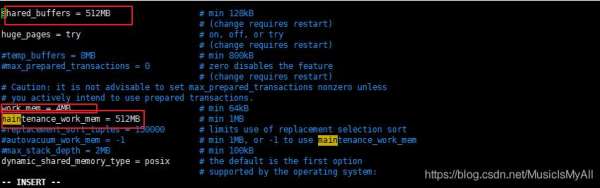
w打开pg的配置文件一看, 我靠,穷鬼呀,才分配了512MB的共享缓存总空间, 进程单独分配了4M空间用于hash,排序等操作,用于维护的分配了512MB。
这哪行,再穷不能穷内存呀! 内从都没有怎么快,怎么快!
一看,服务器有64GB的内存,恨不得都分过去,还好旁边的y阻止了他。
y说不是这么玩的, 共享缓存区的内存一般分配是内存的1/4,不超过总内存的1/2。 线程内存就看着给了,预计下峰值连接数和均值连接数,做一个权衡,适当提高。
于是w将共享缓存区的内存分配为20GB, 单个线程用于hash和排序的分配了200MB。 重启数据库, 跑了下执行计划。 sql里面从以前的一分钟,四五十秒变成了三四秒左右。
仔细看了下执行计划, sort中的磁盘排序变成了内存排序,排序方法从归并变成了快排。 Hash节点中批处理的数量也变成了1, Buffers中缓存全部命中。
到了这里优化看似就完成了,但是还有些不太圆满。 哪里不圆满呢? 明明sql的分页查询语句很快,为什么页面上的分页查询还是要四五秒呢?
一拍脑袋,怎么把这个给忘了, 分页查询页面有个总数统计, 总数统计的sql也需要占时间的呀? 怎么办?
有办法, 不要慌? 我们的原则就是两条腿走路,两个方针政策。
优化全表扫描的速度 (为什么要优化全表扫描的速度,因为统计总数的时候大多数情况下是不能避免全表扫描的)分页查询和统计的sql并行执行怎么实行?
优化全表扫描的速度还得从服务器下手, 全表扫描慢是因为服务器的IO慢,铁蛋恨不得把这个82年的机械硬盘换成SSD,但是人微言轻,只能从其他方面下手: 调大IO预读的大小
#查看当前预读大小
blockdev --getra /dev/vda
#设置预读大小 , 4096的单位是扇区,即512bytes
blockdev --setra 4096 /dev/vda
注意:上面的命令在服务器重启之后失效,所以想永久生效需要将此命令放到 /etc/rc.local 开机自启动脚本中。
sql并行化的实现也比较容易,在一开始就向线程池提交一个统计sql'的任务, 等到分页查询的数据处理完成最后要返回给前端之前找线程池要总数就行了,如果没有执行完,会阻塞等待执行完,所以响应时间就可以控制在sql执行时间最长的那段时间之内了。
至此优化任务算是完成个七七八八了,但是w突然手一抖点了最后一页,哎发现怎么最后一页查询的速度要比第一页慢上一些,怎么回事?
因为如果sql涉及到针对某个字段的排序,那么往后翻页的时候如果采用的是limit offset 的方式会变得很慢,因为数据库需要先把前面的数据都读出来然后扔掉前面不需要的。这个时候一般情况下没有太多sql上的技巧可以优化了,只有在某些个特殊情况下可以采用一些小技巧。
方法是锚点定位法或者叫点位过滤,差不多就这个叫法,知道意思就行。
这个定位是怎么做的呢,如果当你的查询不带过滤条件, (比如你的个人订单记录,只是比较下,不要细纠)。且你的数据中有一个递增且连续的字段(注意一定要连续),那么就可以通过翻页前的最后一条数据的id来定位下一页的位置, 或者直接根据分页大小和要跳转的页码直接定位到你要翻页的地方,一般情况下这个字段是主键。
示例:
select id, time from a order by time limit 10 offset 1000;
//锚点定位就是
select id, time from a where id in (select id from a where id > 1000 limit 10)
order by time
//或者直接
select id, time from a where id > 1000 order by time limit 10
写在最后老师的忠告, 如果在某些情况下通过某个索引去查询的时候因为数据离散存储导致的索引命中之后回表IO放大导致查询缓慢的问题,可以通过CLUSTER 命令强制数据按照某个索引的顺序密集存储。
1cluster a using index_name
如何查看数据是不是离散存储,很简单!! 在selec语句中加上ctid字段。
ctid | id
-------+----
(0,1) | 10
(0,2) | 11
ctid的第一个数字代表块号, 第二个代表行号, 就是第几块的第几行, 所以通过此字段就能看出离散程度。
 13560189272
13560189272  地址:广州市天河区黄埔大道西201号金泽大厦808室
地址:广州市天河区黄埔大道西201号金泽大厦808室 





























