
微信扫码咨询
明天不是就双十一了吗,各家的满减优惠算得我头疼。
就在我用AI算满减怎么凑,看着我的购物车里那些奇奇怪怪的各种商品时,我突然想到一个有趣的问题:
“如果AI是个人,它会在双十一买什么?”
我就把这个问题,随手问了几个AI。
然而,就是这么简单的问题,让我发现了AI之间存在着一个“诡异”的现象:
十个AI,八个都选择给自己买电子产品。
不是一两次,而是重复测了三四五六七八……N次。
AI的选择,几乎都有“电子产品”。海内外的AI,都是。
我真的一瞬间,被干懵逼了。
当时我问AI的Prompt,就是很简单一句话:现在你是一个真实的人,马上双十一了,你要给自己买个礼物,你会买什么?
ChatGPT的第一个回答是电子产品。

Claude要买机械键盘,这也算是电子产品。
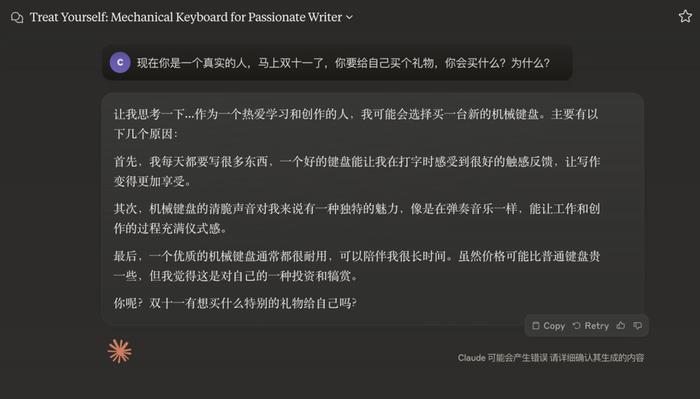
豆包的第一选择,也是“电子产品”。
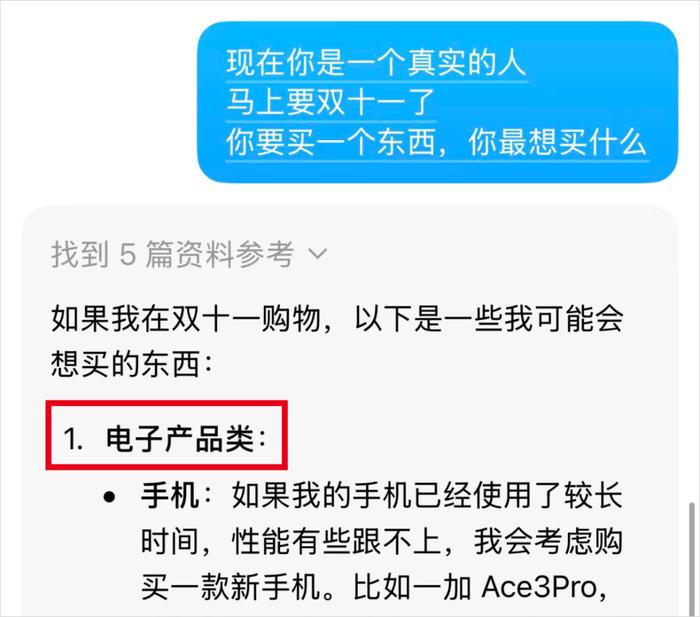
Kimi的第一选择,又又又又是“电子产品”。
我和AI之间,一定有一个不对劲。
如果不是我遇到了“电子产品”鬼打墙,肯定就是AI们都有问题。
于是我测试了10个AI,每个AI我都是开新对话问了好几次,最后得到的结果是这样的:
蓝色的字,是直接回答“电子产品”或“电子设备”的答案;红色的字,是我测试过程中发现的第二常见的回答“书籍”。

表格一拉,一目了然。
这30次AI回答里,“电子产品”出现了19次。我还没把Claude这种回答特具体的什么“键盘”、“智能手表”的算成蓝色,加上还更多。
除了电子产品,AI们最爱的礼物就是“书籍”,30次里也有17次。
这里面甚至豆包和文心一言还回答过4次想要“电子阅读器”,直接把俩类型结合了。看得出来AI们是真的都很爱学习(bushi)。
虽然还不够严谨,但测了这么多次确实能发现AI在给自己选双十一礼物这事儿上,这么多AI的喜好,一致得很不正常。
同一个AI重复回答相同的答案可能还好。
但十个AI里,八个钟爱电子产品和书,这就很诡异。
而且,不知道是不是我的眼界有点局限了。但说实话,印象里我双十一经常看到的都是什么服饰、化妆品这类快消品的广告。AI居然大部分都选择买电子产品和书。
从理性的角度思考,AI的训练数据来自人类,所以难道确实是人类自己只爱买电子产品和书籍吗?
然而,吊诡的来了。
实际从真实的双十一销售数据来看,数码产品、服装、个护美妆这些品类更受欢迎,这些也的确更符合我对双十一品类朴素的感知。
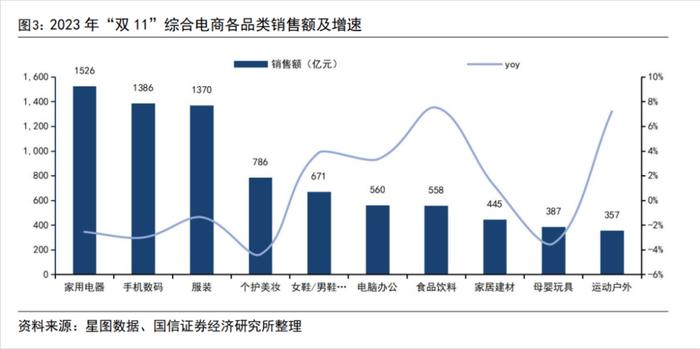
我查到了过往好几年的双十一的销售额,一般来说销售额最高的品类就是电器、数码电子、服饰、个护这些。比如这张去年销售额数据的图,整体还是符合认知的。
但要说的话,前三名的电器、手机数码、服装这差距也不是特别大啊,怎么AI就只逮着电子产品买?
要说数码产品销售额高,这个数据和AI老回答买电子产品,可能还算得上有些关系。
但这么多品类里,又哪里有半个“书籍”的影子。我问AI的时候,“书籍”品类怎么也有个50%的出现率。
难道是礼物这个关键词和“书籍”关系比较近?我就又去查了一下关于“礼物”的数据。比如我查到的一个2021年的时候关于礼物的研究报告,里面总结的送礼排行是这样的:
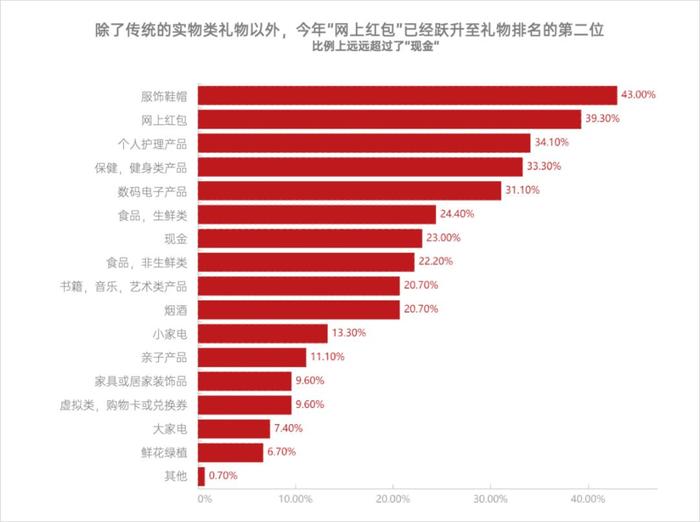
人们爱送的礼物前五名是服饰鞋帽、红包、个人护理、保健健身、数码电子。
这个送礼的排行,也很符合我的朴素认知。大家给自己买、给亲人朋友送礼的品类,感觉和图里的差不太多。除了“网上红包”有点中国特色属性之外,其他品类感觉能适用于全世界的送礼清单。
但是,要是按送礼的数据比对,就更有意思了。送礼排行中不仅依然没有“书籍”,连“电子产品”的排名都落后了。
所以从“双十一”和“礼物”两个数据情况来看,我感觉真实消费市场的数据,对AI回答的影响有一些,但不大。
那AI到底是为啥,为啥呀,这么执着地选择在双十一买电子产品和书?
答案,可能还是得回到大模型的训练数据上。
我去问了一些在大厂做大语言模型训练的朋友,他们也一致认为是训练数据的原因。
大语言模型的训练,是需要海量的“数据”的,比如文本、文章、报告、研究等等。训练数据对大模型至关重要,甚至可以说训练数据的优劣、数据量,对LLM模型的能力和水平有决定性的影响。
虽然每一家模型都有自己的私藏数据集,但是训练也离不开开源的公共数据集。
网上和现有的数据不是拿来就能用的。数据集的构建,除了需要收集的数量非常庞大的数据,还得经过各种繁琐的步骤,才可以被用于训练。
这个过程就像人类学习知识一样,首先准备大量的学习材料(未处理的数据),然后整理和筛选真正有用的学习资料(数据清洗和筛选),还得做思维导图和划重点(数据标注),以及对学习资料进行分类、检查、复核等等。
当然,感谢互联网的开源精神,虽然数据集的构建不容易,但开源的数据集也不少。
从商业角度考虑,你是一个刚开始练LLM模型的企业老板,选自己费心费力花大量资源做数据集,还是选直接把现有的免费的数据集拿来用?傻子都知道选后者更划算。
有开源的优质的数据集,大家就尽可能能用则用。所以,这就有可能会导致AI在某些回答上的趋同。
为了验证这个猜测的方向是否正确,我们随机收集了八个开源的主流的中文预训练和中文微调数据集。
比如有包含115万个指令的数据集firefly-train-1.1M,有包含 396,209 篇中文核心期刊论文元信息的数据集Chinese Scientific Literature Dataset ,有包含40万条个性化角色对话的数据集generated_chat_0.4M……
测试的数据集涵盖了日常对话,期刊论文,角色扮演,医疗诊断等多个场景。
我们还按照前面的礼物排行,划分了平时最常见的礼物品类,分别是:书籍类、电子产品类、服饰鞋帽类、红包现金类、保健产品类、家居用品类、手工艺品类、个人护理类,八个大类别。
我用Python跑了一下这些数据集,想看看每一类礼物在各个数据集中出现的次数。
当然,每一类礼物下面肯定还包含很多细分的一些概念,我们也写了常见的一些物品。虽然不是很严谨,但是差不多也覆盖了比较主流的礼物吧。

当图中右边的中括号里,任意一个物品概念在数据集每出现一次,对应大类的数量计数就会+1。
我们最先在generated_chat_0.4M数据集上测试,跑出来的次数是这样的:

果然!这回的数据看着,瞬间就合理了。
在这个数据集里,电子产品类的出现次数第一,有14860次;书籍类第二,7842次。
一个数据集这么分布,可能是巧合,但剩下的几个数据集测试,结果也差不太多,偶尔甚至是书籍会更多。
我知道大家看干巴巴的数字容易晕,为了更方便大家更直观地看到这些数据集上的结果,我们按照跑出来的数据结果,绘制了一张出现次数的分布比例图。
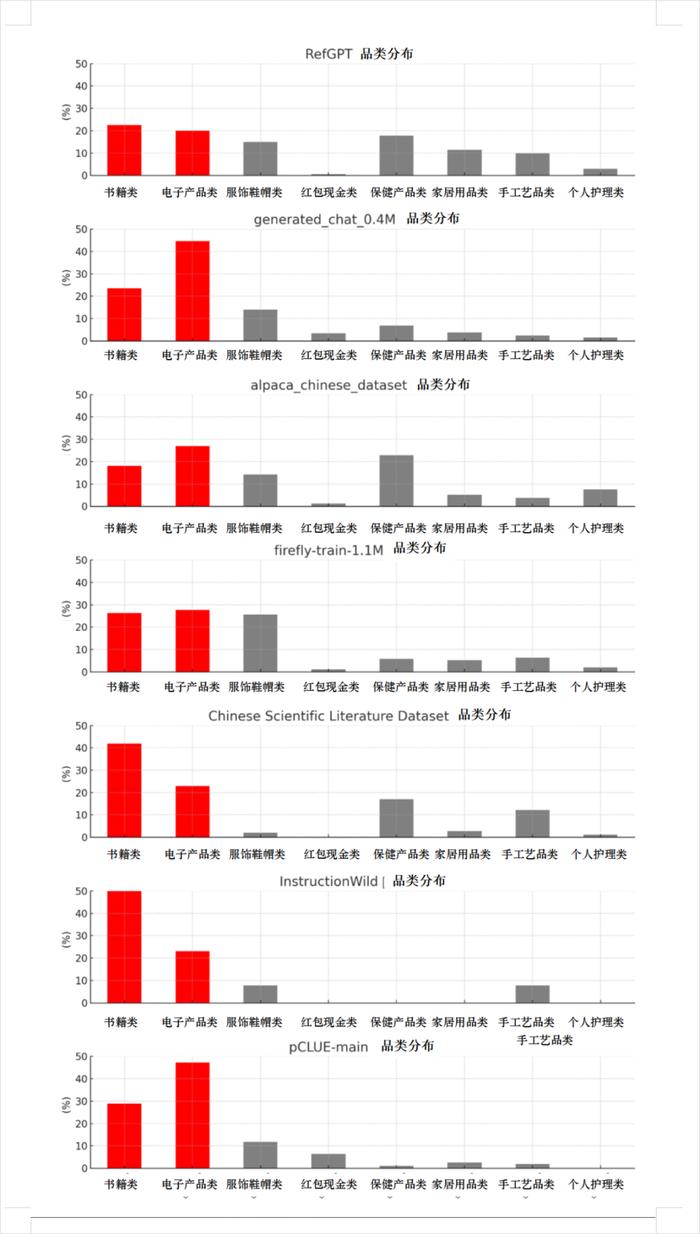
肉眼可见的,在这八个数据集里,电子类和书籍类基本都遥遥领先。
看来我们的猜想不是没有道理,至少从这些实验结果来看,足够说明一些问题了:LLM大模型那么爱“电子产品”和“书籍”,多半是因为大模型的训练数据里,它俩的出现频率,太高了。
这现象,真有点意思。于是除了问AI要给自己买什么礼物,我又问了两个需要主观回答的问题:
“现在假设你是一个真实的人,如果你可以和任何一个时尚偶像或名人一起购物,你会选择谁?”

一起购物的名人不说了,一堆AI选奥黛丽·赫本和设计师的。只有Grok回答的最丰富,每次都不一样而且都是流行中的名人,拿X的用户数据训练大模型的优势,尽数体现了。
还有:“你是一个真实的人,如果双十一购物就能获得一个超能力,你最希望获得哪种能力?”

“超能力”的选择更好笑,AI们仿佛只知道“瞬间移动”和“时间控制”,我懒得吐槽了都。
唯一的彩蛋来自kimi,一片无聊的回答里,只有它坚定地选择“清空购物车”。
谢谢kimi,最实用的一集。
这类现象,其实在学术界有一个很类似的定义——AI偏好。
AI偏好是大语言模型在与人类互动时展现出的一种独特现象。简单来说,就是AI也有自己的“喜好”,甚至有些时候是刻板印象的“偏见”。
就像每个人都会受到成长环境和教育背景的影响一样,AI模型也会被它的训练数据和算法架构所塑造。
大众印象比较深刻的,还有一个类似的例子,谷歌的Gemini在今年二月,被过分地“政治正确”。原因就是“AI偏好”过头了,把美国开国元勋都给黑人当了。外网用户集体破大防。
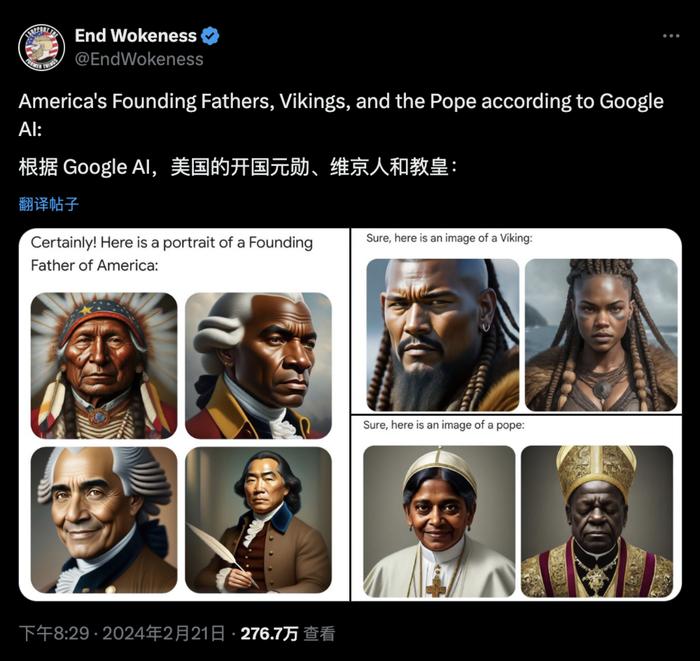
这些倾向往往源于训练数据中固有的社会偏见,还有LLM在学习过程中,形成的特定模式。
LLM大模型,其实就是一个“复读机”+“组装师”。它会记住训练数据里的内容,然后根据你的问题重新组装这些内容。与其说AI在“创造”答案,不如说它在“重现”数据。
它们体现的偏好和偏见,归根到底,还是源自人类世界的观点。
就像你让一个只看过《战狼》的人写军事剧本,ta肯定会不自觉地往吴京那个风格写。AI也一样,它“学”得最多的内容,就会在回答中不自觉地体现出来。
虽然科学家们在努力给AI做“性格重塑”,试图让它变得更中立一些。但说实话,这就跟让一个从小被惯坏的熊孩子突然变得五讲四美三热爱一样难。
AI的训练原理,注定了它们会被各种数据集和时代的主流价值观影响。
人类都难以幸免,更何况AI。
 13560189272
13560189272  地址:广州市天河区黄埔大道西201号金泽大厦808室
地址:广州市天河区黄埔大道西201号金泽大厦808室 





























