
微信扫码咨询
今天是春运的第一天,大家都抢到票了吗?有多少打工人是定时抢票,不停地刷新网页,最后仍然不得不花大价钱买“抢票加速包”才买到票的?
这两天关于“12306 已申请防止自动抢票专利”的新闻冲上热搜,引发广大网友的关注。
那么,为什么有了软件加持,就真的能买到紧缺的车票呢?如何才能防止自动抢票呢?今天从技术的角度来聊聊。
网上购票时,到底发生了什么?
在 12306 上买火车票,和在淘宝、京东这些电商网站上买东西,基本的流程是相似的,大概可以分成登录、查询、选择、确认、支付这样几个步骤。
登录是购票的前提,它会验证使用者的身份是否是自己声称的身份,涉及个人信息的确认。
其原理也很简单:用户输入自己的用户名和登录密码,购票系统在自己的用户数据库中查询,看看用户名和密码是否正确。如果正确的话,就认为用户身份可信。
在这一阶段,风险在于用户身份可能被仿冒。仿冒者可能会大量尝试不同的密码,或者使用其他网站泄露的密码,来仿冒真正的用户身份。
而通用的解决方案是双管齐下:当用户连续几次输错密码,就在一段时间内禁止登录;以及在用户输入密码后,再经过一个验证步骤,来让用户拖拽拼图,或者在一系列图片中找到符合要求的图片。
过去的 12306 曾因为验证难度过高而为人诟病——在早期,12306 的第一次验证通过比例只有可怜的 8%。当然,在经过多年持续改进后,这一问题已经被解决得差不多了。
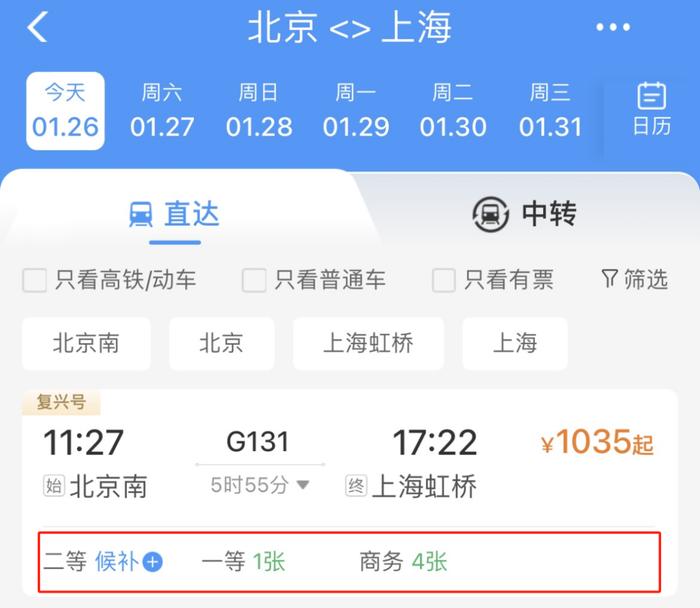
确认了用户身份后,接下来就是一路坦途。用户先根据自己的出发地和到达地查询余票情况,然后选择自己想要的车次;然后选择乘车人和座位信息,确认选择正确后,支付票款。
这个过程,其实和用户把身份证递给火车站售票处的工作人员、由工作人员代为选票的过程是一样的,只不过实现了完全自助而已。
有余票时,这个过程当然没有问题,大家按照先来后到的顺序逐一购票就好。但若是余票不足,而大家又都想买到票,那么就不免有人想要上一些技术手段了。
为什么技术手段可能可以抢到票?
购票时的技术手段,就是自动化抢票。自动化抢票的基本思路,是让计算机模拟人的行为。
个人使用:若是开发一个仅仅自己使用的自动化抢票程序,还是比较简单的。先用自己的个人信息登录,人工通过身份验证,然后以较高的频率持续查询想要的车次,当查询返回的数据表示有余票时,马上下订单。
此时的关键,在于分析返回的查询结果。而这也不难,毕竟查询结果是返回的一串文字,从中提取信息比较容易。这就像是站在售票处窗口,过两分钟就问一次有没有票一样,反正 12306 的服务器是机器而不是售票处工作人员,只要计算能力允许就能做到有问必答,不会觉得这样问来问去很烦。
多人使用:而若是要为许多人抢票,就会麻烦一些。帮助用户登录和通过验证比较麻烦,毕竟让计算机像人那样识别图形、通过验证过程还是有些难度的——验证码发明出来,就是为了让计算机难以冒充人。
不过既然是技术问题,那往往也就会有技术解决方案。随着计算机视觉技术的发展,攻破图形验证码并不是难以做到的事情,只是拉高了技术门槛而已。
所以自动化抢票的过程,就像是一群人堵在售票处窗口,过几秒钟就有人过来问一遍有没有票,直到买到票或者过了售票时间才罢休。

自动化抢票会带来几个后果:对那些规规矩矩排队买票的用户不公平;浪费了 12306 服务器的计算资源,可能降低 12306 用户的购票体验;以及降低了所有用户的幸福感——没有买到票的用户自然不高兴,而加了钱抢到票的用户也未必开心。
所以当然,为了防止自动化抢票,也该有相应的技术手段才是。
如何防止自动化抢票?
有几个基本思路可以提高自动化抢票的技术难度。
1.识别来自自动化抢票软件的行为,找到那些自动化抢票的机器黄牛。
具体而言,可以通过分析服务器的访问情况,筛选出那些短时间内频繁查询车票信息的机器,禁止它们访问;而自动化抢票软件为了对应这一方案,则往往会采取频繁更换 IP 地址的方式。所以这种思路,只能作为基础。
2.让自动化抢票软件无法获得有效的余票信息。
如前所述,我们向 12306 上发起的每次余票查询,都会向用户的浏览器返回一串文字,而抢票软件会分析这串文字,获取余票信息。如果返回的不是文字,抢票软件要处理起来就会麻烦得多。毕竟计算机视觉和人类视觉很不一样,人能一眼看出来的东西,计算机识别起来并不容易。
2021 年 11 月,中国铁道科学研究院电子计算技术研究所申请了一项名叫《一种防止自动抢票方法及系统、设备和存储介质》的专利,采用的就是这种思路。在这项专利中,研究者把查询后的余票信息转换成了可伸缩矢量图像(SVG,Scalable Vector Graph),再发送回用户的浏览器上。
SVG 是一种很有意思的图像格式。它是图像,但却用文字来描述图像中的位置、颜色、线条宽度等等信息;它使用相对点来保存数据,因此可以缩放到任意大小而不会失真。这两个特征,让它既可以容易地通过程序绘制,也适合出现在任意大小的显示器上。
在放自动化抢票上,它的这两个特征就很有用了:查询返回的是图片,传统的自动化抢票软件无法从中提取出和车票信息相关的文字,自然也就无法抢票。而手动购票的用户,能识别出这些图片中的车票信息,依然只需点击想要的车次信息,就可以继续购票。
在上文所述专利中,也提出了一种巧妙的验证方式:使用文字组合,实现基于文字推理的行为验证。就是让用户在购票前再通过一次行为验证。
具体而言,大概像是这样:首先,随机选择几个汉字,把它们转成 SVG 图像,再分成上下两部分。然后,展示这些汉字的上半部分,和其中一个字的下半部分。最后,让用户找到正确的拼合方式,只有组成正确的汉字,才算通过验证。

自动化抢票软件要通过这种验证,则需要“认字”才行,也就是说需要拥有一个字库,以及能够对照字库寻找正确的拼合方法,这无疑会增加自动化抢票的难度。
总而言之,要防自动化抢票,就要为购票系统设计一些障碍,这些障碍对于人来说不难,而对于计算机来说暂时还很难。
毕竟需求就是动力,计算机的能力也会提升。技术会逐步升级,自动化抢票和反自动化抢票会是一场持续的拉锯战。
 13560189272
13560189272  地址:广州市天河区黄埔大道西201号金泽大厦808室
地址:广州市天河区黄埔大道西201号金泽大厦808室 





























